Représenter des caractères
Des nombres pour représenter des caractères
La représentation des caractères dans un ordinateur passe par l'attribution d'un numéro unique à chacun d'eux.
En théorie c'est facile en pratique pas vraiment :
il faut que chaque interface utilise le même encodage
il faut représenter tous les caractères dont les "non imprimables", c'est à dire toutes les touches du clavier et au delà
il faut utiliser le moins de mémoire possible.
Codage ASCII
Rappel :
Dans les années 50 il y avait de nombreux systèmes d'encodages qui étaient incompatibles.
Au début des années 60, l'ANSI (American National Standards Institute) définit la norme ASCII (American Standard Code for Information Interchange).
Définition : Codage ASCII
La norme définit un jeu de 128 caractères représentés sur un octet.
L'association entre un caractère et son octet, ici son nombre hexadécimal à deux chiffres est donnée par le tableau suivant.
La ligne d'entête donne le premier chiffre du nombre hexadécimal, la première colonne donne le 2e chiffre.
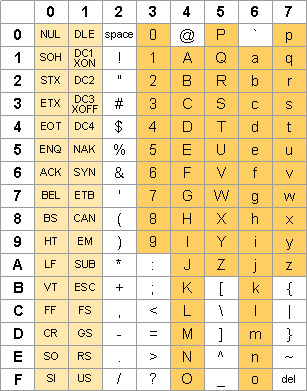
Exemple : Applications
Pour le caractère 'A' on trouve l'hexadécimal 41, soit le nombre 65.
Pour l'hexadécimal 2B on trouve le caractère...
Enfin proposer un caractère et son code hexadécimal.
Remarque :
Dans la table ASCII il y a plusieurs catégories de caractères : lettres en majuscules, minuscules, les chiffres, les signes de ponctuation, des opérateurs arithmétiques.
Mais on y trouve aussi des caractères spéciaux (espace, tabulation,etc.) et des caractères non imprimables, de contrôle ( début d'en-tête, son sur haut-parleur,etc.).
Attention : Retour à la ligne dans les OS
Les caractères LF (Line Feed, nouvelle ligne) et CR (Carriage return, retour cchariot) sont nécessaires sous Windows pour démarrer une nouvelle ligne alors que sous GNU/Linux LF suffit.
Simulation : Le codage ASCII des caractères sous Python
La fonction ord() renvoie le code ASCII du caractère correspondant en décimal. On rajoute la fonction hex() pour obtenir sa valeur hexadécimale.
>>>ord('a')
97>>>hex(ord('a'))
'0x61'Inversement la fonction chr() renvoie le caractère correspondant à un entier.
Attention en fait ces deux fonctions manipulent l'Unicode (cf plus loin partie Unicode).
>>>chr(38)
'&'>>>chr(0x7B)
'{'La saisie directe par l'intermédiaire du caractère d'échappement \ en mettant derrière le code hexadécimal sous la forme xhh.
>>>print('\x40')
'@'>>>print('\x45\x63\x72\x69\x72\x65\x20\x21')
Ecrire !
Il existe aussi des raccourcis pour accéder aux caractères spéciaux :
\a BEL (son sur le haut-parleur)
\n LF (nouvelle ligne)
\r CR (retour chariot)
\t HT (tabulation horizontale)
\v VT (tabulation verticale)
\\ pour afficher le caractère \
>>>print('Hello \tworld \n Bienvenue \vsur \vcet \vaffichage \a')
Hello world
Bienvenue sur cet affichage Complément : Bit de parité
Dans cet encodage on représente 128 caractères. Donc on n'a besoin que de 7 bits. Or on utilise un octet en mémoire. Donc le bit de poids fort est utilisé comme somme de contrôle pour détecter d'éventuelles erreurs.
Ce bit est positionné pour que le nombre de bits à 1 dans l'octet soit toujours pair.
Normes ISO 8859
On remarque immédiatement que la table ASCII est insuffisante pour transmettre les textes accentués, les symboles de monnaies, etc.
Définition :
A partir de l'année 1986, l'ISO (International Standard Organisation : Organisation Internationale de Normalisation) propose de coder les caractères sur un octet. Cela fait donc 256 caractères potentiels. C'est la norme ISO 8859. Mais cela reste insuffisant.
Pour augmenter le nombre de caractère elle crée donc 16 tables de correspondances ISO 8859-n où n est le numéro de la table.
Les 128 premiers caractères sont ceux de la norme ASCII. Les 128 autres sont ceux spécifiques à la table. Les caractères identiques ont le même code d'une table à l'autre.
Les tables sont liées à la nature de la langue :
8859-1 (latin1) Europe occidentale
8859-2 (latin2) Europe centrale ou de l'est
....
8859-9(latin9) révision du latin 1 pour intégrer €
etc.
L'unicode
La séparation des tables dans la norme 8859 n'est pas toujours possibles quand on a besoin de tous les caractères simultanément .
Définition : Norme ISO-10646
L'ISO a donc défini un jeu universel de caractères (UCS : Universel Character Set) sous la norme ISO-10646 disponible à partir de l'année 1990.
A chaque caractère (lettre, nombre, idéogramme,etc.) est associé son unique nom et son numéro (entier positif en base 10 : point de code).
Il y a 110000 caractères recensés dans cette norme dont la capacité maximale est de \(32^2\) c'est à dire le plus grand entier non signé représentable sur 32 bits.
Par soucis de compatibilité les 256 premiers caractères sont ceux de la norme ISO-8859-1.
Syntaxe :
On utilise la notation U+xxxx ou chaque x est un chiffre hexadécimal, pour désigner les points de code du jeu universel de caractères.
Par exemple U+006F désigne la lettre o (point de code 111 dans le jeu de caractère universel mais aussi dans la table latin-1 mais aussi dans la table ASCII).
Remarque :
Les caractère les plus utilisés dans le monde ont un point de code compris entre 0 et 65535 soit deux octets. Donc la plupart du temps le codage sur 32 bits est surdimensionné et constitue un gâchis d'usage de la mémoire. Il faut donc optimiser l'utilisation des ressources.
Définition : UTF-8
La norme unicode développée par le consortium du même nom apparaît en parallèle de la norme ISO-10646 au début des années 1990. Elle propose de représenter les points de code de façon optimisée.
Ses encodages sont appelés UTF (Universal Transformation Format) et se note UTF-n où n représente le nombre minimal de bits pour représenter un point de code.
Donc UTF-8 nécessite seulement 8 bits pour coder les premiers caractères et est entièrement compatible avec l'ASCII. Par conséquent les programmes codé en ASCII devraient fonctionner en UTF-8. C'est le format le plus utilisé sous GNU/Linux et les protocoles réseaux.
Principe :
si le bit de poids fort est 0 alors il s'agit d'un caractère ASCII codé sur les 7 bits restants
sinon les premiers bits de poids fort indiquent le nombre d'octets utilisés pour encoder le caractère à l'aide d'une séquence de 1 se terminant par 0.
Enfin chacun des octets suivants l'octet de poids fort est de la forme 10xx xxxx
Plage | Suite d'octets (binaire) | bits codant |
|---|---|---|
U+0000 à U+007F U+0080 à U+07FF U+0800 à U+FFFF U+10000 à U+10FFFF | 0xxx xxxx 110x xxx 10xx xxxx 1110 xxxx 10xx xxxx 10xx xxxx 1111 0xxx 10xx xxxx 10xx xxxx 10xx xxxx | 7 bits 11 bits 16 bits 21bits |
La version d'UTF8 ne permet un codage que sur 4 octets maximum.
Exemple : Représentation de points de code en format UTF-8
Point de code | Point de code en binaire | UTF-8 en binaire |
|---|---|---|
U+004B U+00C5 U+0A9C | 0100 1011 1100 0101 0000 1010 1001 1100 | 0100 1011 1100 0011 1000 0101 1110 0000 1010 1010 1001 1100 |
Simulation : Unicode et Python
En Python les chaînes de caractères sont des séquences au format UTF8. On peut donc utiliser les caractères UTF8 même pour les noms dans le code et pas seulement dans une chaîne.
Ces caractères peuvent être saisi directement avec leur point de code sous la forme : \uxxxx où les x sont les chiffres hexadécimaux ou avec leur nom (unique) du UCS.
>>>'\u004B'
'K'>>>'\u00C5'
'Å'>>>s = '\u00E7\u0061\u0020\u0065\u0074\u0020\u006C\u00E0'
>>>print(s)
ça et là
>>> '\N{LATIN SMALL LETTER SHARP S}'
'ß'On peut utiliser les méthodes de chaînes de caractères encode() et decode() pour connaître l'encodage d'une chaîne et inversement :
>>>c='\u0A9C'
>>>c.encode()
b'\xe0\xaa\x9c'>>>'ça et là'.encode()
b'\xc3\xa7a et l\xc3\xa0'On reconnaît la chaîne d'octets à l'aide de la nomenclature b'...' et le fait qu'ils sont données en notation hexadécimal avec \x...
Seuls les caractère autres que ASCII sont affichés en hexadécimal, les autres sont simplement affichés comme caractères.
>>> b'\xC3\x85'.decode()
'Å'Complément : la bibliothèque unicodedata
Pour aller plus loin dans l'utilisation des caractères et de l'encodage unicode on peut faire appelle à la bibliothèque unicodedata.
import unicodedata
u = chr(233) + chr(0x0bf2) + chr(3972) + chr(6000) + chr(13231)
for i, c in enumerate(u):
print(i, '%04x' % ord(c), unicodedata.category(c), end=" ")
print(unicodedata.name(c))
Cela affiche :
0 00e9 Ll LATIN SMALL LETTER E WITH ACUTE
1 0bf2 No TAMIL NUMBER ONE THOUSAND
2 0f84 Mn TIBETAN MARK HALANTA
3 1770 Lo TAGBANWA LETTER SA
4 33af So SQUARE RAD OVER S SQUARED
sources : https://docs.python.org/fr/3/howto/unicode.html
Définition : UTF16 et 32
UTF16 utilise 16 bits au minimum pour représenter un caractère et seuls les points de code entre U+0000 et U+10FFFF peut être représentés.
UTF16 représente les 65536 (\(2^{16}\)) premiers points de code sur 2 octets. Les points de code suivants sont représentés sur 4 octets.
UTF-32 n'est pas économique puisqu'il représente tous les caractères sur 32 bits mais simplifie les manipulations de chaînes de caractères puisqu'ils occupent tous la même place en mémoire.